

Bibliographical Data Science: from Catalogues to Research Data
Library catalogues have been identified as a crucial resource for studying different aspects of book production spanning from literature to intellectual history and to informatics. At the same time, using them requires addressing challenges of data quality, completeness, and interpretation. Important aspect of bibliographic data science workflow is that it is imagined as a multilingual and transnational way of approaching large humanities and social science data. Data from national libraries for example covers hundreds of years of data and several languages. When we look at the possibility of combining different library datasets from multiple countries, we often face the challenge of dealing with language dependencies and deduplication.
The core of this type of work is to iterate between data harmonisation, analysis built upon different use cases and validating the data against other sources. We should imagine an open science ecosystem of different metadata collections where work on one of them also eases the use of another. Ecosystem thinking is important also because the harmonisation step often depends on other linked sources such as authority files or other library catalogues. An approach through which library metadata catalogues become research data has been coined as bibliographic data science. In this workflow description, we explain what it takes to produce research data out of library catalogues. The workflow can be described as an open science initiative because it takes questions of reproducibility and data quality seriously.
This workflow provides a step-by-step guide for researchers eager to use bibliographical data for research. More specifically, it looks into common issues of data acquisition, preprocessing, harmonisation, analysis and validation as well as an array of dissemination options.
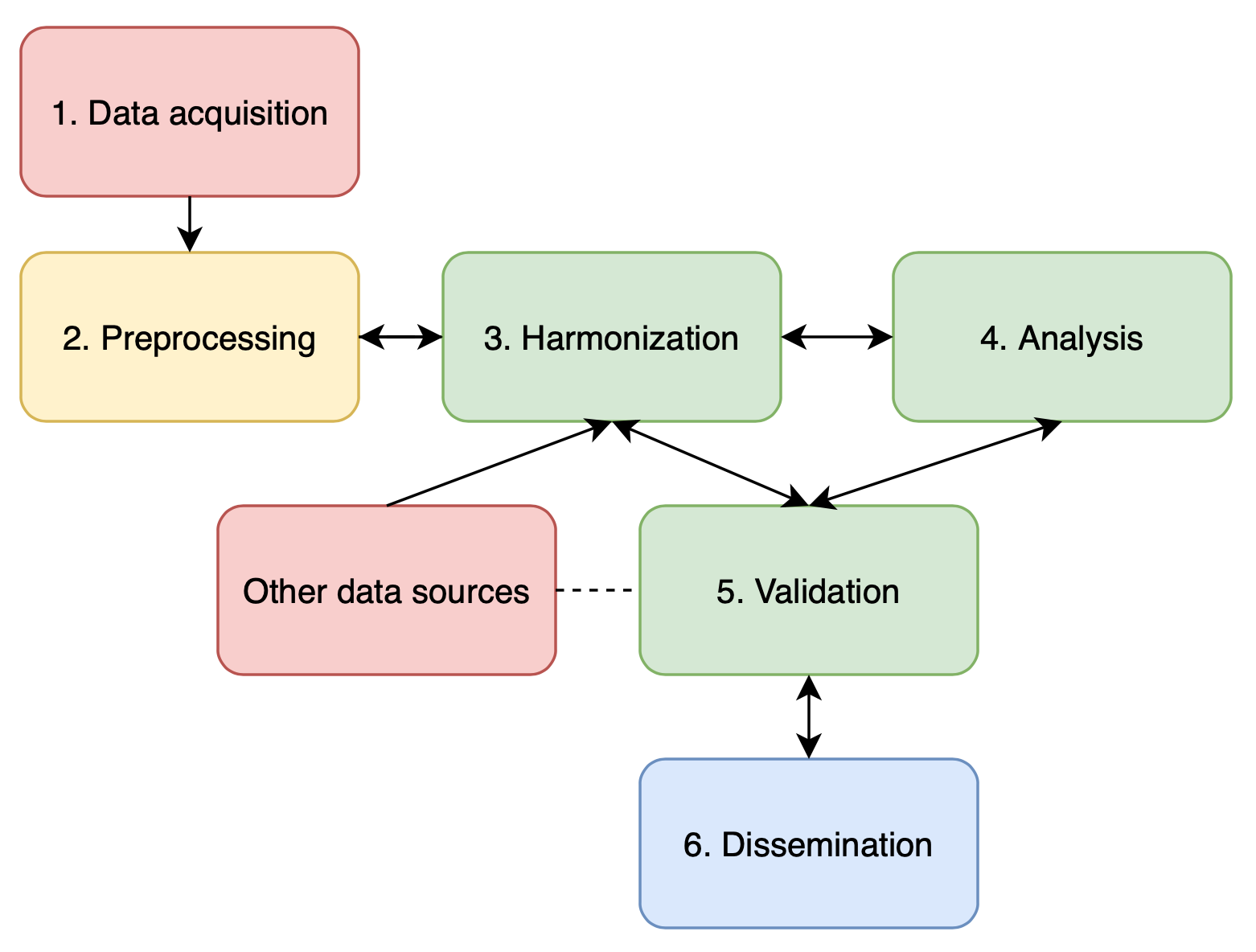
Workflow steps(6)
1 Data acquisition
2 Preprocessing
3 Harmonisation
4 Analysis
5 Validation
6 Dissemination


The SSH Open Marketplace is maintained and will be further developed by three European Research Infrastructures - DARIAH, CLARIN and CESSDA - and their national partners. It was developed as part of the "Social Sciences and Humanities Open Cloud" SSHOC project, European Union's Horizon 2020 project call H2020-INFRAEOSC-04-2018, grant agreement #823782.
